
38KB
title: Deep Learning Through the Lens of the Information Plane author: rhnvrm type: post date: 2017-12-21T14:31:58+00:00 url: blog/2017/12/21/deep-learning-through-the-lens-of-the-information-plane/ categories:
- projects tags:
- datascience
- deeplearning
- informationtheory
- math
- neuralnetwork
- python
The ridiculous effectiveness of Deep Learning has lead to research on tools that help to analyze these Deep Neural Network based “black boxes”. Recent research papers by the Information Theory community to analyze has rise to a new tool, The Information Plane, which can help analyze and answer various questions about these networks. This article, provides a brief overview of the concepts from information theory required to develop an understanding of the Information Plane, followed by a replication study of the implementation of the paper that introduces this theory with respect to Deep Neural Networks.
1. Introduction
Information Theory has long been considered marginal to Statistical Learning theory and has usually not been studied by Machine Learning researchers. It is considered to be an integral part of Communication Engineering and is often known to be the theory of Data Compression and Error Correcting Codes. With increased compute power enabled through GPUs, a new interest in Deep Learning (LeCun et al.1) has re-emerged. Although, Deep Learning provides ridiculous effectiveness, there is pretty much no fundamental theory behind these machines and they are often criticized for being used as mysterious “black boxes”2. This has lead to major corporations like Intel investing in research that focuses on building an understating of why deep networks work the way they do and has resulted in the recent paper on “Opening the Black Box of Deep Neural Networks via Information Theory” by Ravid Schwartz-Ziv and Naftali Tishby 2 which studies these by analyzing their information-theoretic properties and tries to provide a framework to study them using the Information Plane which have been based upon the work done by Naftali Tishby earlier 3. The theory provides tools, such as the Information Plane, that can be used to reason about what happens during deep learning, a study of what happens during Deep Neural Network (DNN) learning during training and some hints for how the results can be applied to improve the efficiency of deep learning.
One of the observations from the paper 2 is that DNN training involves two distinct phases: First, the network trains to fully represent the input data and minimize the error in generalization and then, it learns to forget the irrelevant details by compressing the representation of the input.
Another observation is a potential explanation for why transfer learning works when the top most layers are retrained for similar tasks, but I skip it for further work as it is beyond the scope of this current study, although it has been mentioned while discussing the Asymptotic Equipartition Property.
From an engineering standpoint, the papers provide a very relevant theory which could help answer questions such as, if the trained model is optimal or not, if there exist any design principles for such machines, or if the layers or neurons represent anything and if the algorithms we use can be improved or not.
The following paper contributes via providing an overview of the fundamentals of Information Theory required to study these papers, followed by a detailed summary of the work related to the Information Plane and Deep Learning and finally a replication study containing a re implementation study and its results and comparison with the results of the original authors as well as the critics of the paper. The goal of the paper was to dive into cutting edge research and implement the state of the art and verify the results of both the original authors [2] [3] as well as the critique 4 submitted to ICML 2018.
2. Concepts from Information Theory
2.1 Markov Chain
A Markov process is a “memory-less” (also called “Markov Property”) stochastic process. A Markov chain is a type of Markov process containing multiple discrete states. That is being said, the conditional probability of future states of the process is only determined by the current state and does not depend on the past states. 5
2.2 KL Divergence
KL divergence measures how one probability distribution 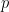




2.3 Mutual Information
Mutual information measures the mutual dependence between two variables. It quantifies the “amount of information” obtained about one random variable through the other random variable. Mutual information is symmetric. 5

2.4 Data Processing Inequality
For any markov chain: 

A deep neural network can be viewed as a Markov chain, and thus when we are moving down the layers of a DNN, the mutual information between the layer and the input can only decrease.
2.5 Reparameterization Invariance
For two invertible functions 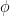
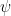

For example, if we shuffle the weights in one layer of DNN, it would not affect the mutual information between this layer and another.
2.6 The Asymptotic Equipartition Property
This theorem is a simple consequence of the weak law of large numbers. It states that if a set of values 



where 
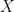
Although, this is out of bounds of the scope of this work, for the sake of completeness I would like to mention how the authors of 2 use this to argue that for a typical hypothesis class the size of 





Then the input compression bound,

becomes,

The authors then further develop this to provide a general bound on learning by combining it with the Information Bottleneck theory [6].
3. Information Theory of Deep Learning
3.1 DNN Layers as Markov Chain
In supervised learning, the training data contains sampled observations from the joint distribution of 


 , input layer , hidden layers
, input layer , hidden layers  and the final prediction . (Image Source: Tishby 2015)[3]
and the final prediction . (Image Source: Tishby 2015)[3] as in Figure above, we can view each layer as one state of a Markov Chain:
as in Figure above, we can view each layer as one state of a Markov Chain:  . According to DPI, we would have:
. According to DPI, we would have:
 A DNN is designed to learn how to describe to predict and eventually, to compress to only hold the information related to . Tishby describes this processing as “successive refinement of relevant information” [3].
A DNN is designed to learn how to describe to predict and eventually, to compress to only hold the information related to . Tishby describes this processing as “successive refinement of relevant information” [3].
 . (Image Source: Schwartz-Ziv and Tishby 2017 [2])in about preserve information, we don’t really care which individual neurons within the layers encode which features of the input. This can be captured by finding the mutual information of
. (Image Source: Schwartz-Ziv and Tishby 2017 [2])in about preserve information, we don’t really care which individual neurons within the layers encode which features of the input. This can be captured by finding the mutual information of  with respect to and . Schwartz-Ziv and Tishby (2017) treat the whole layer, , as a single random variable, charachterized by
with respect to and . Schwartz-Ziv and Tishby (2017) treat the whole layer, , as a single random variable, charachterized by  and
and  , the encoder and decoder distributions respectively, and use the Reparameterization Invariance given in [(2)][1] to argue that since layers related by invertible re-parameterization appear in the same point, each information path in the plane corresponds to many different DNN’s, with possibly very different architectures. [3]
, the encoder and decoder distributions respectively, and use the Reparameterization Invariance given in [(2)][1] to argue that since layers related by invertible re-parameterization appear in the same point, each information path in the plane corresponds to many different DNN’s, with possibly very different architectures. [3]
 This is to say that after training, when the trained network, the new input passes through the layers which form a Markov Chain, to the predicted output . The information plane has been discussed further in Section [3][2].
### **3.2 The Information Plane**
Using the representation in Fig. [3][3], the encoder and decoder distributions; the encoder can be seen as a representation of , while the decoder translates the information in the current layer to the target output .
The information can be interpreted and visualized as a plot between the encoder mutual information
This is to say that after training, when the trained network, the new input passes through the layers which form a Markov Chain, to the predicted output . The information plane has been discussed further in Section [3][2].
### **3.2 The Information Plane**
Using the representation in Fig. [3][3], the encoder and decoder distributions; the encoder can be seen as a representation of , while the decoder translates the information in the current layer to the target output .
The information can be interpreted and visualized as a plot between the encoder mutual information  and the decoder mutual information
and the decoder mutual information  ;
;


 is what we expect to see from cross-entropy loss minimization. The second diffusion phase minimizes the mutual information
is what we expect to see from cross-entropy loss minimization. The second diffusion phase minimizes the mutual information  – in other words, we’re discarding information in X that is irrelevant to the task at hand.
A consequence of this is pointed out by Schwartz-Ziv and Tishby indicating that there is a huge number of different networks with essentially optimal performance, and attempts to interpret single weights or even single neurons in such networks can be meaningless due to the randomised nature of the final weights of the DNN. [2]
## **4. Experimental Setup and Results**
### **4.1. Experimental Setup**
The experiments were done on a network with 7 fully connected hidden layers, and widths 12-10-7-5-4-3-2 neurons, similar to what had been done in the original paper. The network is trained using Stochiastic Gradient Descent and cross-entropy loss function, but no other explicit regularization. The activation functions are hyperbolic tangent in all layers but the final one, where a sigmoid function is used. The bin count was taken to be 24 for the mutual information calculation. Off the shelf python libraries such as Tensorflow[8], NumPy[9], ScikitLearn[9] were used for the re-implementation as described by the original paper.
Variations were made to the activation function to Rectified Linear Unit (ReLu) and Sigmoidal to verify the results of a recent paper [4] which is under open review for ICLR 2018 under the same conditions.
### **4.2. Results**
– in other words, we’re discarding information in X that is irrelevant to the task at hand.
A consequence of this is pointed out by Schwartz-Ziv and Tishby indicating that there is a huge number of different networks with essentially optimal performance, and attempts to interpret single weights or even single neurons in such networks can be meaningless due to the randomised nature of the final weights of the DNN. [2]
## **4. Experimental Setup and Results**
### **4.1. Experimental Setup**
The experiments were done on a network with 7 fully connected hidden layers, and widths 12-10-7-5-4-3-2 neurons, similar to what had been done in the original paper. The network is trained using Stochiastic Gradient Descent and cross-entropy loss function, but no other explicit regularization. The activation functions are hyperbolic tangent in all layers but the final one, where a sigmoid function is used. The bin count was taken to be 24 for the mutual information calculation. Off the shelf python libraries such as Tensorflow[8], NumPy[9], ScikitLearn[9] were used for the re-implementation as described by the original paper.
Variations were made to the activation function to Rectified Linear Unit (ReLu) and Sigmoidal to verify the results of a recent paper [4] which is under open review for ICLR 2018 under the same conditions.
### **4.2. Results** 

 and the Y-Axis represents
and the Y-Axis represents 
The results were plotted using the experimental setup and tanh as the activation function. It is important to note that it’s the lowest layer which appears in the top-right of this plot (maintains the most mutual information), and the top-most layer which appears in the bottom-left (has retained almost no mutual information before any training). So the information path being followed goes from the top-right corner to the bottom-left traveling down the slope.
Early on the points shoot up and to the right, as the hidden layers learn to retain more mutual information both with the input and also as needed to predict the output. But after a while, a phase shift occurs, and points move more slowly up and to the left.

and the Y-Axis represents  and the Y-Axis represents
and the Y-Axis represents  and the Y-Axis represents
and the Y-Axis represents  and the Y-Axis represents
and the Y-Axis represents 4.3. Analysis
The results of using the hyperbolic tan function (tanh) as the choice for activation function corresponds with results obtained by Schwartz-Ziv and Tishby (2017) 2. Although, the same can’t be said about the results obtained when ReLu or Sigmoid function was used as the activation function. The network seems to stabilize much faster when trained with ReLu but does not show any of the charachteristics mentioned by Schwartz-Ziv and Tishby (2017) such as compression and diffusion in the information plane. This is in line with 4, although the authors have commented in the open review 4 that they have used other strategies for binning during MI calculation which give correct results. The compression and diffusion phases can be clearly seen in Fig. 4. The corresponding plot of the loss function also shows that the DNN actually learned the input variable
References
1 Y. LeCun, Y. Bengio, and G. E. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. [Online]. Available: http://sci-hub.tw/10.1038/nature14539
2 R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,” CoRR, vol. abs/1703.00810, 2017. [Online]. Available: http://arxiv.org/abs/1703.00810
3 N. Tishby and N. Zaslavsky, “Deep learning and the information bottleneck principle,” CoRR, vol. abs/1503.02406, 2015. [Online]. Available: http://arxiv.org/abs/1503.02406
4 Anonymous, “On the information bottleneck theory of deep learning,” International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=ry WPG-A-
5 T. M. Cover and J. A. Thomas, Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience, 2006.
[6] N. Tishby, F. C. N. Pereira, and W. Bialek, “The information bottleneck method,” CoRR, vol. physics/0004057, 2000. [Online]. Available: http://arxiv.org/abs/physics/0004057
[7] L.Weng. Anatomize deep learning with informa-tion theory. [Online]. Available: https://lilianweng.github.io/lillog/2017/09/28/anatomize-deep-learning-with-information-theory.html
[8] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng, “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015, software available from tensorflow.org. [Online]. Available: https://www.tensorflow.org/
[9] E. Jones, T. Oliphant, P. Peterson et al., “SciPy: Open source scientific tools for Python,” 2001–, [Online; accessed ¡today¿]. [Online]. Available: http://www.scipy.org/
[10] S. Prabh. Prof. shashi prabh homepage. [Online]. Available: https://sites.google.com/a/snu.edu.in/shashi-prabh/home
[11] N. Wolchover. New theory cracks open the black box of deep learning — quanta magazine. Quanta Magazine. [On-line]. Available: https://www.quantamagazine.org/new-theory-cracks-
open-the-black-box-of-deep-learning-20170921/
[12] Machine learning subreddit. [Online]. Available: https://www.reddit.com/r/MachineLearning/
This work has been undertaken in the Course Project component for the elective titled “Information Theory (Fall 2017)” [https://sites.google.com/a/snu.edu.in/shashi-prabh/teaching/information-theory-2017] at Shiv Nadar University under the guidance of Prof. Shashi Prabh